GPU架构
实时渲染的要求:高质量+速度快,要想做到能在质量上逼近离线渲染同时还要能在大多数平台上跑,就必须要优化,要去优化就涉及到shader是如何运行的,所以抽了个时间简单了解了一下GPU的架构以及shader的运行流程,这里做个总结。
和CPU做对比GPU只有很少的逻辑控制并且没有Cache,简单来说GPU的运行机制就是Raster Engine与SM之间的数据交换。
GPU大概结构
GPU被划分成多个GPC(Graphics Processing Cluster,图形处理簇),每个GPC拥有多个SM(SMX、SMM,Streaming Multiprocessor 流式多处理器 是GPU的基础单元,隔壁AMD叫CU)和一个光栅化引擎(Raster Engine),这些部件通过总线所连接。
Shader代码就是经过编译之后在SM上运行,一般来说SM越多性能也就越好,因为SM里面就包含着运算的单元:Core
GPU的数据储存在DRAM中,访问速度慢,CPU、GPU都可以访问。
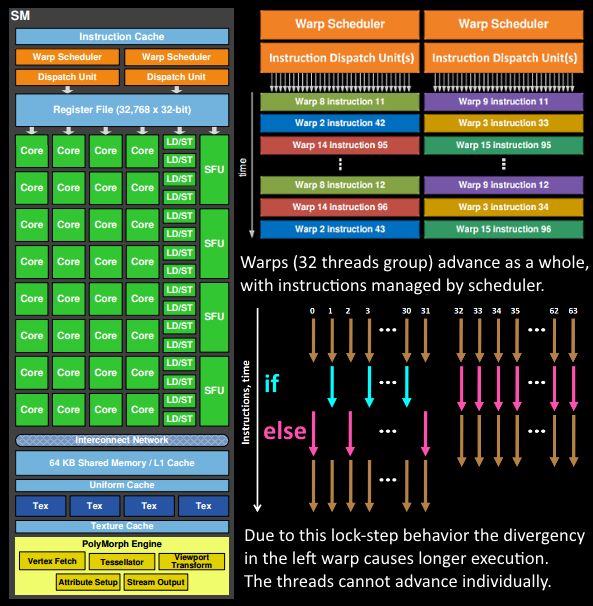
SM的结构
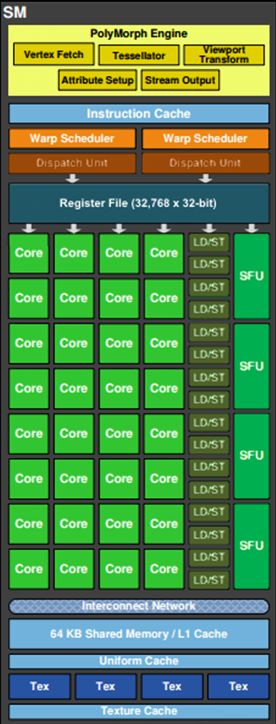
里面的结构有:
- PolyMorph Engine:多边形引擎负责属性装配(attribute Setup)、顶点拉取(VertexFetch)、曲面细分、栅格化(这个模块可以理解专门处理顶点相关的东西)。
- 指令缓存(Instruction Cache)
- 2个Warp Schedulers:这个模块负责warp调度,一个warp由32个线程组成,warp调度器的指令通过Dispatch Units送到Core执行。
- 指令调度单元(Dispatch Units) 负责将Warp Schedulers的指令送往Core执行
- 128KB Register File(寄存器)
- 16个LD/ST(load/store)用来加载和存储数据
- Core (Core,也叫流处理器Stream Processor)
- 4个SFU(Special function units 特殊运算单元)执行特殊数学运算(sin、cos、log等)
- 内部链接网络(Interconnect Network)
- 64KB 共享缓存
- 全局内存缓存(Uniform Cache)
- 纹理读取单元(Tex)
- 纹理缓存(Texture Cache)存rendertexture的地方
在Shader中的语义,对应的就是GPU中缓存Buffer的位置,在需要计算时,会从固定位置找需要的数据。
GPU逻辑管线
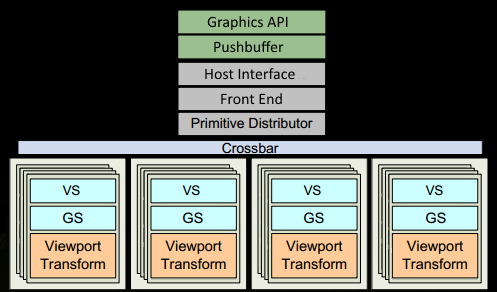
- 程序在图形 API(DirectX 或 openGL)中进行绘图调用(drawcall)然后数据会被GPU可读编码后插入到Pushbuffer中。DC的瓶颈就是在这里出现的。
- 一段时间后或者显式刷新(explicit “flush” calls)后,驱动程序已在pushbuffer 中缓冲了足够的work并将其发送给 GPU 进行处理(在操作系统的某些参与下)。GPU 的Host Interface接收通过Front End处理。
- 数据完全到达GPU后,在图元分配器(Primitive Distributor)中开始工作分配,处理indexbuffer,将处理得到的三角形分成batch,发送给多个GPC。
在进入GPC之后:
- 在GPC中,每个SM中的Poly Morph Engine负责通过三角形索引(triangle indices)取出三角形的数据(vertex data),即下图中的Vertex Fetch模块。
- 在获取数据之后,在SM中以32个线程为一组的线程束(Warp)来调度,来开始处理顶点数据。
处理完顶点数据之后:
- 运算结果会被Viewport Transform模块处理,三角形会被裁剪然后准备光栅化,GPU会使用L1和L2缓存来进行vertex-shader和pixel-shader的数据通信。
- 接下来这些三角形将被分割,再分配给多个GPC,三角形的范围决定着它将被分配到哪个光栅引擎(raster engines),每个raster engines覆盖了多个屏幕上的tile。
- GPC上的光栅引擎(raster engines)在它接收到的三角形上工作,来负责这些这些三角形的像素信息的生成(同时会处理裁剪Clipping、背面剔除和Early-Z剔除)。
- 32个像素线程将被分成一组,或者说8个2x2的像素块,这是在像素着色器上面的最小工作单元,在这个像素线程内,如果没有被三角形覆盖就会被遮掩,SM中的warp调度器会管理像素着色器的任务。
值得注意的是Wrap中所需要的数据是合并一次生成,所以所有的core都执行完毕之后才会停止这一次的流处理,然后把数据传递给光栅化着色器。这就解释了为什么shader中要少用循环语句,特别是未知循环次数的循环语句,因为所有的core都需要等“运气最不好的那个core”执行完毕,这样一来就有可能会达到长的耗时。对于if else语句也是一样的,这个线程的结束不取决于条件真假,而取决于整个wrap何时结束。
然后也要少在shader里面做三角函数运算,可以看到SM里面只分配了四个做特殊函数运算的单元,他们和core之间还需要做数据交换。
GrabPass耗时的原因:GPU可以把当前要渲染的渲染到一个中间缓冲中,这就是一个texture,CPU需要拿到储存在缓冲的这个texture,然后又拷贝到GPU的另一个指定GPC中去参与运算,就是一个非常耗时的过程。(RenderToTexture的实现是:将FBO直接关联到GPU的Texture上,所以数据不需要拷贝回CPU)。



