Draw Call
要绘制某些东西,CPU必须告诉GPU要绘制什么以及如何绘制,每次CPU准备好数据向GPU发送绘制命令就是Draw Call。
Unity SRP 的shader语言现在采用的不是CG,而是HLSL,理由大概就是CG已经很久没有更新了,已经落后了,Unity使用的就是HLSL,而SRP的Shader使用HLSLPROGRAM以及.hlsl的原因就是本来使用的就是hlsl编译器,同时也没有必要支持旧的built-in的头文件。
HLSL
创建一个新的Unlit Shader,删掉默认的CG代码,使用HLSL去写Shader代码。
设置好基本的两个着色器,然后要自己写好需要incude的file,文件结构如下:
1 | Shader "Unlit/Unlit" |
防止在文件被包含一次以上的情况下导致代码重复:
UnityPass.hlsl中的代码:
1 |
|
Common.hlsl:
1 |
|
UnityInput.hlsl,放我们需要的各种内置矩阵、变量:
1 |
|
这样这个hlslshader就能正确编译,得到一个circle:
Core Library
刚刚定义的两个函数其实就包含在Core RP Pipeline包中。核心库定义了许多更有用和重要的东西,所以直接使用这个包就行了,不用什么都自己写。
在Common.hlsl里面:
1 |
对于UnlitPass.hlsl,增加一个颜色控制:
1 | float4 _BaseColor; |
在shader里暴露出这个参数:
1 | Properties |
SRP Batcher
unity2018之后引入的超厉害的东西,正常的drawcall是很花时间的,srp批处理就能很好地缓解这个问题。它在GPU上缓存材质属性,这样它们就不必在每次绘制调用时都发送。但DrawCall的数量本身是没有变的,只是每次不需要再向GPU传送材质数据,GPU会自动得到缓存的数据。
批处理所需的材质属性必须在一个具体的内存缓冲区中定义,而不是在全局。这通过UnityPerMaterial名称将BaseColor声明包装在cbuffer块中来实现。这样就把_BaseColor放在一个特定的常量内存缓冲区中,但它仍然可以在全局级别上访问。通常这个会用CBUFFER_START CBUFFER_END来代替,避免有些平台不支持。
1 | CBUFFER_START(UnityPerMaterial) |
将要使用的属性全部定义在缓冲区之后,再编译这个材质,就变成compatible了:

shader compatible之后,就是在管线中enable SRP batcher,因为只需要在管线创建时启动就好,在构造方法里enable就行:
1 | public CustomRenderPipeline() |
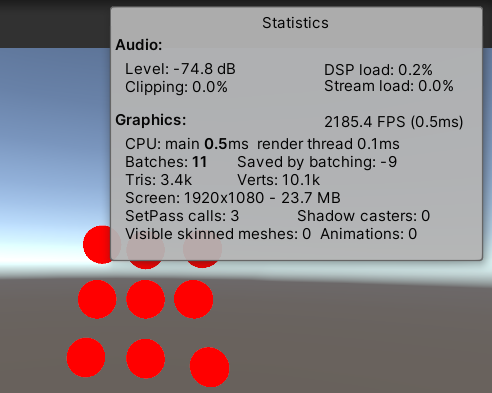
使用了Batcher之后,同样是渲染9个unlit材质的物体,有9个batch saved了
材质参数修改
之所以能够batch,是因为每个物体都使用了一样的材质,这时如果去修改_baseColor的值,所有的物体颜色都会变,下面使用MaterialPropertyBlock去实现单独修改物体材质属性:
1 | public class PerObjectMaterialProperties : MonoBehaviour { |
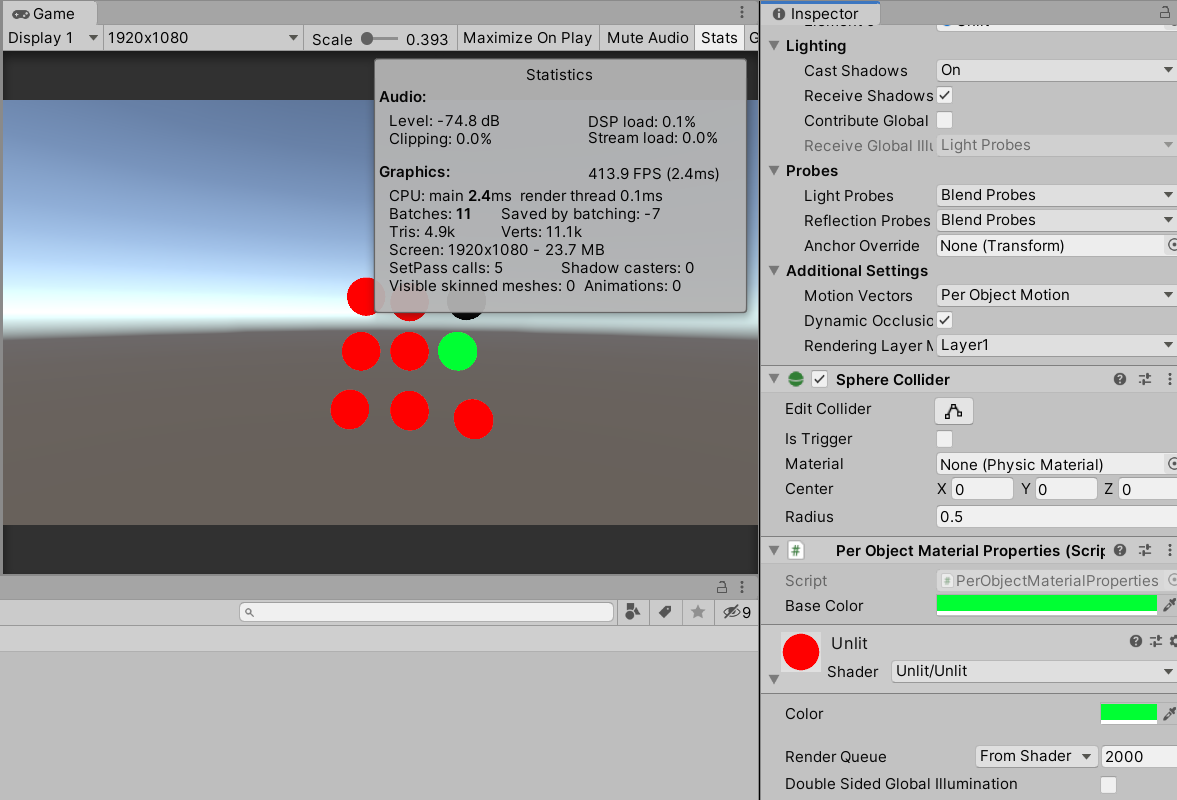
这样就可以单独修改共用材质物体的颜色,但同时SRP batcher的数量也会变少,因为不支持这种单独属性。
GPU Instancing
另外一种优化的方法就是GPU实例化,它可以在共用材质的情况下减少batch的数量。
原理:如果绘制1000个物体,它将一个模型的vbo提交给一次给显卡,至于1000个物体不同的位置,状态,颜色等等将他们整合成一个per instance attribute的buffer给gpu,在显卡上区别绘制,它大大减少提交次数。即可以只用一个DrawCall,和附带的参数,画出很多物体。而在其中一个实例化单位时,GPU会根据目前这个实例化单位的索引,从Buffer中获取对应的属性,比如位置颜色等等。
首先加上支持GPU Instancing的渲染指令:#pragma multi_compile_instancing,然后材质面板上就会出现是否实例化的勾选框,然后在材质里面勾选:
然后需要引入一个Library:UnityInstancing.hlsl,它所做的是重新定义一些宏来访问实例化的数据数组。但要做到这一点,它需要知道当前被渲染对象的索引,索引是通过顶点数据提供的。所以在输入的顶点属性结构体里面要给出它的引索ID:UNITY_VERTEX_INPUT_INSTANCE_ID
定义在a2v、v2f结构体中,生成索引
UNITY_INSTANCING_BUFFER_START ~ END
用于在这个起止区域内定义属性,这些属性就是实例化单位需要用到的属性,只有写在这里的属性才能通过索引正确得到
UNITY_SETUP_INSTANCE_ID
定义在着色器的起始位置,使顶点着色器(或片段着色器)可以正确的访问到实例化单位的索引
UNITY_TRANSFER_INSTANCE_ID
引索拷贝,在片段着色器中,把输入结构的引索复制到输出结构
UNITY_ACCESS_INSTANCED_PROP
得到这个单位在Buffer中对应的属性
1 | UNITY_INSTANCING_BUFFER_START(UnityPerMaterial) |
对于fragment同样也要它的ID,并且同样需要使用一个宏去让Index Enable:
1 | float4 UnlitPassFragment (Varyings input) : SV_TARGET { |
现在unity就可以只使用一个batch去渲染这些共用了材质的物体,而且这些物体都有自己的可调变的材质属性,在FrameDebug里面你只看得到一个drawmesh:
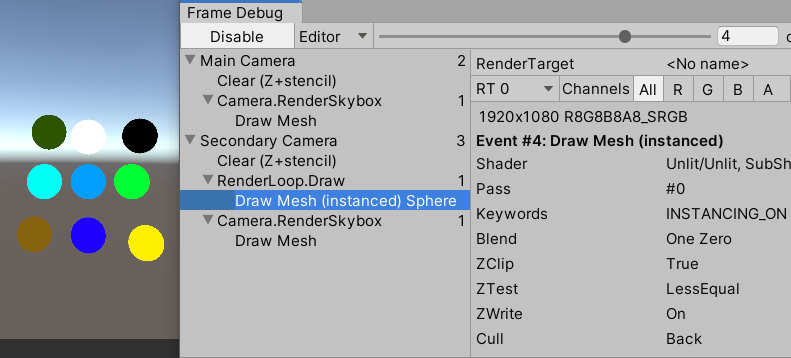
一个batch的大小也是有限制的,当超过这个限制的时候,就要用到多个batch了。
Drawing Many Instanced Meshes
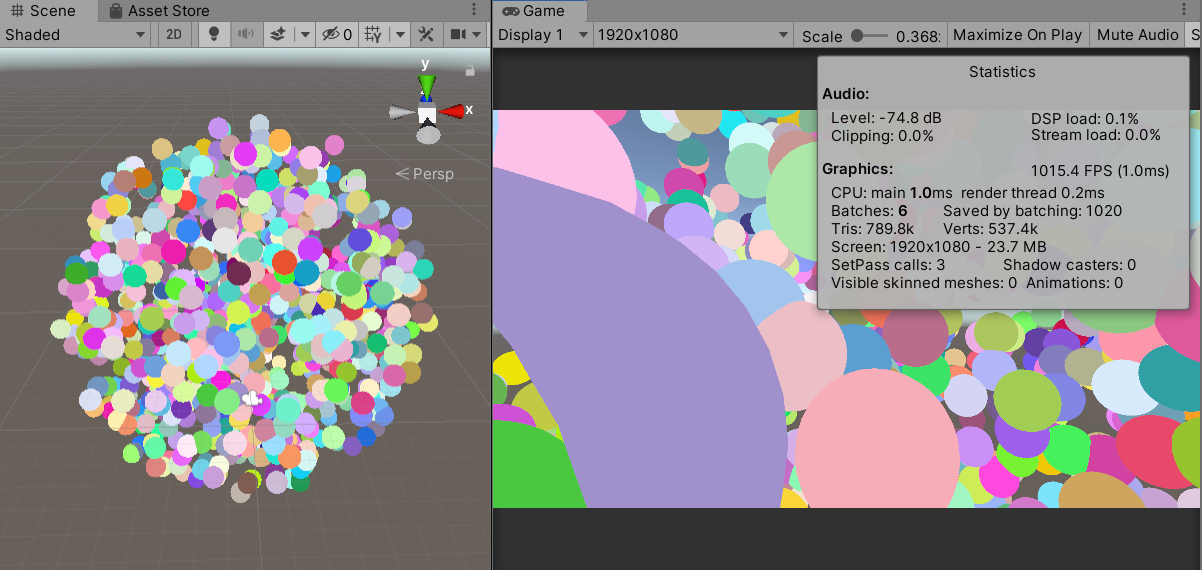
创建一个挂着MeshBall的物体,实现使用一个drawcall去渲染成百上千的物体。unity可以在update函数中调用DrawMeshInstanced实现批次渲染。
Dynamic Batching
第三种减少DrawCall的方法,将多个共享相同材质的mesh组合成一个更大的mesh,然后绘制出来。
改变DrawSettings的参数,disable掉SRP Batch
1 | var drawingSettings = new DrawingSettings( |
Transparency
后面来创建不透明材质,不透明和透明渲染之间的主要区别在于是如何处理之前的渲染结果和之后渲染的结果之间的混合。所以直接在Unlit Shader里面进行修改就可以:
1 | [] _SrcBlend ("Src Blend", Float) = 1 |
然后用Blend指令就可以定义透明效果。而且渲染透明物体时,需要关闭深度写入。



